



The landscape of the modern desktop is undergoing a profound transformation. As artificial intelligence moves from the experimental fringes into the core of our operating systems, users are increasingly demanding tools that are not only powerful but also private and respectful of system resources. Canonical, the company behind the world’s most popular Linux distribution, Ubuntu, has officially taken the next step in its long-term AI strategy.
Following a strategic roadmap unveiled earlier this year, Canonical has introduced Myna, a dedicated speech-to-text (STT) engine slated for debut in Ubuntu 26.10 this October. Designed as a cornerstone of Ubuntu’s "implicit AI" framework, Myna promises to bring professional-grade voice dictation to the Linux desktop—entirely offline, locally processed, and architecturally optimized for accessibility.
The Strategic Roadmap: From Implicit to Explicit AI
To understand the significance of Myna, one must first look at the framework established by Jon Seager, Canonical’s engineering lead, back in April. Canonical’s vision for AI in Ubuntu is bifurcated into two distinct categories:
- Implicit AI: These are the "silent" features designed to improve the user experience without requiring explicit interaction. They are meant to be seamless, efficient, and unobtrusive—functioning as background utilities that make daily computing tasks faster or more accessible.
- Explicit AI: These are features that the user intentionally summons—active assistants, generative tools, or complex problem-solving agents that require a direct query or trigger from the user.
Myna falls squarely into the "Implicit AI" category. It is not an AI assistant that waits for a command or attempts to automate your life; it is a tool meant to bridge the gap between human speech and digital text, acting as a functional extension of the keyboard. By focusing on utility over gimmickry, Canonical is signaling a pragmatic approach to AI integration—one that prioritizes privacy and stability over the buzzword-heavy features often found in competing operating systems.
Chronology: The Path to Myna
The journey toward Myna began with a broader corporate shift at Canonical toward integrating machine learning into the Ubuntu Desktop experience.

- April 2026: Jon Seager publicly outlines Canonical’s AI philosophy, emphasizing the necessity of local, privacy-centric models. The framework for "implicit" versus "explicit" AI is established, setting the stage for future development.
- May 2026: Development work on the speech-to-text engine accelerates. Canonical engineers begin prototyping the "Speech Orchestrator" and "Audio Adapter" components.
- June 2026: Canonical officially announces Myna. The project is introduced via a technical post on the Ubuntu Discourse forum, inviting community feedback and setting a release target for the Ubuntu 26.10 cycle.
- October 2026 (Upcoming): Scheduled release of Ubuntu 26.10, which will include the initial implementation of Myna.
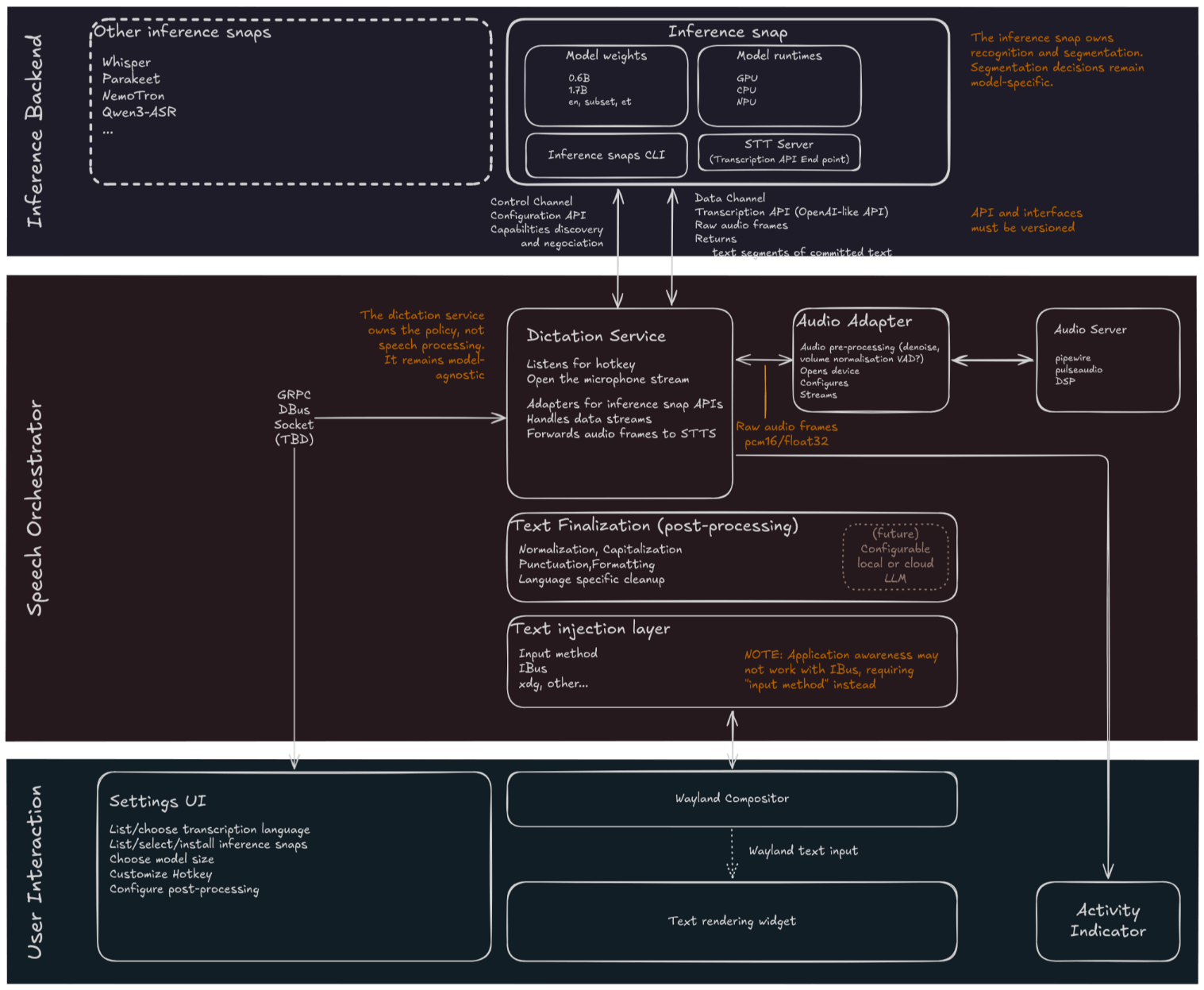
Technical Architecture: How Myna Functions
Myna’s architecture is designed for modularity and efficiency. Because Linux users often run a wide range of hardware—from low-power ARM-based laptops to high-end workstations with dedicated GPUs—the system has been built with a "hardware-agnostic" mindset.
The Canonical Inference Snap
At the heart of the system is the Canonical Inference Snap. This containerized component holds the intelligence of the model. To accommodate varying hardware capabilities, Canonical is offering three tiers of models:
- Lightweight: Optimized for power efficiency and older hardware.
- Default: The standard balance between accuracy and performance.
- Quality: A larger, more intensive model for users with high-end hardware (NVIDIA GPUs or dedicated NPUs) who prioritize transcription precision.
The Pipeline: From Mic to Text
The data flow within Myna is designed to be as brief and secure as possible:
- Audio Adapter: This component captures input from the microphone. It handles the critical work of noise cancellation and audio chunking, ensuring that only clean, relevant data is passed to the inference engine.
- Speech Orchestrator: This acts as the session manager. It handles the "Push-to-Talk" logic, ensuring that the microphone only captures audio when the user intentionally triggers the function.
- Local Inference: Once the audio is processed, it is sent to the Inference Snap. Critically, this happens entirely on-device. No audio data ever leaves the local environment.
- Finalized Output: Unlike some web-based services that stream text as it is being processed—leading to that "jittery" display of half-formed words—Myna is designed to output text only once the transcription is finalized.
Privacy as a Design Pillar
In an era where "cloud-based AI" is often synonymous with "data harvesting," Canonical has taken a firm stance on privacy. Myna is built from the ground up to be offline-first. Once the chosen model is downloaded, the user does not need an internet connection to utilize the dictation features.
Furthermore, the data lifecycle is exceptionally short. Audio data is stored in a volatile in-memory buffer, which is wiped the moment the dictation session concludes. This prevents the storage of personal voice recordings on the local disk, further minimizing the attack surface and alleviating privacy concerns for enterprise and privacy-conscious users.

The Scope of Accessibility and Constraints
Jean-Baptiste Lallement, Director of Engineering for Ubuntu Desktop, has been clear about what Myna is and, perhaps more importantly, what it is not.
For the initial launch in 26.10, the feature is strictly a desktop dictation tool. To maintain focus and performance, the following features are explicitly excluded from the current development roadmap:
- Wake words: Myna will not be "always-listening."
- Voice commands: It is not designed to control the operating system or launch applications.
- Speaker identification: It cannot differentiate between multiple voices.
- Continuous listening: It is restricted to the Push-to-Talk mechanism.
- Translation and Language Detection: The initial release is focused on stable, high-accuracy English transcription.
This restrained feature set is a deliberate choice. By avoiding the "everything-at-once" approach, Canonical aims to deliver a stable, bug-free experience that serves as a reliable accessibility aid rather than a bloated, experimental assistant.
Implications for the Linux Ecosystem
The introduction of Myna is a bellwether for the future of Linux. For years, Linux has lagged behind macOS and Windows in terms of native, high-quality accessibility tools. The lack of a standard, system-wide speech-to-text engine has historically forced users to rely on third-party, often unstable, or proprietary cloud-based solutions.
By embedding Myna directly into the GNOME/Wayland stack, Canonical is providing a standardized interface that could eventually be adopted by other distributions. If successful, Myna could serve as the "Gold Standard" for local AI integration on Linux, proving that the open-source community does not need to rely on Big Tech’s cloud infrastructure to provide modern computing features.
Getting Involved: The Road to 26.10
As it stands, Myna is still in its infancy. The project’s GitHub repository is currently a skeleton, hosting the initial documentation and architectural specifications. This is intentional. Canonical is actively soliciting feedback from the community—particularly from those in the accessibility community who rely on assistive technology to interact with their computers daily.
The success of Myna will depend on its performance across diverse hardware configurations. As daily builds of Ubuntu 26.10 begin to roll out, developers and early adopters will be the primary testers. The feedback gathered during this period will be instrumental in refining the "Speech Orchestrator" and determining the final performance tuning for the three model sizes.
Conclusion
Canonical’s decision to pursue Myna is a sophisticated move. It acknowledges that the future of the OS is tied to AI, but it refuses to compromise on the core tenets of the Ubuntu project: privacy, control, and local execution.
While the feature set may seem modest to those accustomed to the hyper-ambitious marketing of commercial AI, Myna represents a vital, functional, and necessary evolution for the Ubuntu desktop. By starting with a focused, high-quality dictation tool, Canonical is laying the groundwork for a future where AI feels like a natural, invisible extension of the operating system—a tool that empowers the user, rather than one that monitors them. As we look toward the release of Ubuntu 26.10, Myna stands as a testament to the fact that when it comes to AI, the most impressive features are often the ones that simply work exactly as promised.
